
쿠폰 발급에 관한 상세사항은 [Git Issues] 참고
흐름
[1] 발급 요청 수신
↓
[2] Redis 재고 조회
↓
[3] 재고 DECR
- 재고 부족이면 → 발급 실패
↓
[4] 발급 성공
- 재고 DECR 상태 유지큰 흐름은 위와 같다.
다만 여기에서는 Redis에 해당 Key가 만료되어 사라지거나 다른 문제로 없어졌다면 어떻게 해야할지와
DECR만 할 뿐 발급 내역을 따로 저장하는 로직이 포함되어 있지 않아서 추가했다.
[1] 발급 요청 수신
↓
[2] Redis 재고 조회
- 없으면 → DB 조회 → Redis 복구
↓
[3] 재고 DECR
- 재고 부족이면 → 발급 실패
↓
[4] 발급 성공
- 발급 성공 이력을 Kafka/Redis Stream 등에 publish
↓
[5] DB Worker가 Queue를 읽어서 batch로 coupon_issues 테이블에 insert- 재고 조회 시 Redis 에 없으면 DB 조회해서 Redis 에 등록
- 발급성공 시 Redis Stream에 Publish
- DB Worker 생성 후 coupon_issues 테이블에 내역 업데이트
Redis Stream
여기서 Redis Stream에 대해 알아봐야했다. Kafka의 메시지 큐와 같은 기능이라고 이해했다.
(단순히 알림만 보낼거라면 Redis Pub/Sub를 사용하라고 한다. 이건 다음에 찾아보기로)
| 항목 | Redis Stream | RabbitMQ/Kafka |
| 속도 | 매우 빠름 (RAM 기반) | 빠름 (디스크 기반) |
| 신뢰성 | 메모리+디스크 조합 | 디스크 기반이라 더 높음 (특히 Kafka) |
| 스케일링 | Redis Cluster로 확장 가능 | Kafka는 수평 확장 매우 강력 |
| 운영 편의성 | 비교적 간단 (하지만 운영 관리 필요) | Kafka는 운영 난이도 높음, RabbitMQ는 중간 정도 |
| 사용 예 | 실시간 데이터 처리 (ex: 센서 데이터 수집) | 대규모 이벤트 스트리밍, 대용량 데이터 파이프라인 |
대규모 트래픽에는 Kafka를 쓰는게 좋다고 한다.
하지만 경험삼아 Redis Stream으로 구현을 시도해봤다.
CouponWorker 적용
// 발급 성공 Redis Stream에 기록
Map<String, String> message = new HashMap<>();
message.put("couponId", String.valueOf(couponId));
message.put("userId", "testUser");
redisTemplate.opsForStream().add(CouponConstants.STREAM_KEY, message);쿠폰 발급이 정상적으로 처리되면 Redis Stream에 CouponId와 User를 넘긴다.
@Scheduled(fixedDelay = 5000) // 5초마다 실행
public void consumeCouponIssuedStream() {
try {
List<MapRecord<String, Object, Object>> messages = redisTemplate.opsForStream()
.read(
Consumer.from(CouponConstants.GROUP_NAME, CouponConstants.CONSUMER_NAME),
StreamReadOptions.empty().count(10).block(Duration.ofSeconds(1)),
StreamOffset.create(CouponConstants.STREAM_KEY, ReadOffset.lastConsumed())
);
....
...
..5초는 실시간성으로 보면 적합하진 않으나, 1초마다 했을 때 생기는 DB 부하가 걱정되어서 이와같이 설정했다.
Consumer.from(GROUP_NAME, CONSUMER_NAME)
나는 GROUP_NAME 그룹 안의 CONSUMER_NAME이라는 이름을 가진 Consumer야.
그룹 내부에서 내 처리를 추적하고 관리할 수 있도록 할게.
treamReadOptions.empty().count(10).block(Duration.ofSeconds(1))
메시지를 최대 10개까지 읽을게. 없으면 1초 동안 기다려볼게. 그래도 없으면 그냥 빈 리스트 반환할게.
- 한 번에 너무 많은 메시지를 가져오지 않도록 조절.
- 대기(block)를 통해 불필요한 폴링을 줄이고 효율적으로 읽기.
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed())
내가 이미 읽었던 메시지 이후로, 아직 읽지 않은 메시지만 가져올게.
- 이미 처리한 메시지를 중복 처리하지 않기 위해 사용.
- Consumer Group은 Redis가 "이 Consumer는 어디까지 읽었는지"를 기억하고 관리한다.
* Worker 전체 코드
@Scheduled(fixedDelay = 5000) // 5초마다 실행
public void consumeCouponIssuedStream() {
try {
List<MapRecord<String, Object, Object>> messages = redisTemplate.opsForStream()
.read(
Consumer.from(CouponConstants.GROUP_NAME, CouponConstants.CONSUMER_NAME),
StreamReadOptions.empty().count(10).block(Duration.ofSeconds(1)),
StreamOffset.create(CouponConstants.STREAM_KEY, ReadOffset.lastConsumed())
);
if (ObjectUtils.isEmpty(messages)) {
return;
}
for (MapRecord<String, Object, Object> message : messages) {
try {
Map<Object, Object> value = message.getValue();
String couponIdStr = String.valueOf(value.get("couponId"));
String userId = String.valueOf(value.get("userId"));
log.info("Processing coupon issue event: couponId={}, userId={}", couponIdStr, userId);
CouponIssues issued = CouponIssues.builder()
.coupons(Coupons.builder().id(Long.parseLong(couponIdStr)).build())
.userId(userId)
.build();
couponIssuesRepository.save(issued);
// 처리 완료된 메시지 ack
redisTemplate.opsForStream()
.acknowledge(CouponConstants.STREAM_KEY, CouponConstants.GROUP_NAME, message.getId());
} catch (Exception e) {
log.error("ERROR!", e);
}
}
} catch (Exception e) {
log.error("Error while consuming coupon issue stream", e);
}
}
StreamInitializer
@PostConstruct
public void initStreamAndGroup() {
try {
// 1. Stream 키가 존재하는지 확인
boolean streamExists = redisTemplate.hasKey(CouponConstants.STREAM_KEY);
if (!streamExists) {
log.info("Stream '{}' does not exist. Creating dummy record...", CouponConstants.STREAM_KEY);
// Stream이 없으면 dummy 데이터 하나 넣어서 스트림 생성
redisTemplate.opsForStream().add(
StreamRecords.newRecord()
.ofObject("init")
.withStreamKey(CouponConstants.STREAM_KEY)
);
}
// 2. Consumer Group 존재하는지 확인하고 없으면 생성
try {
redisTemplate.opsForStream().createGroup(CouponConstants.STREAM_KEY, CouponConstants.GROUP_NAME);
log.info("Consumer Group '{}' created for Stream '{}'.", CouponConstants.GROUP_NAME, CouponConstants.STREAM_KEY);
} catch (DataAccessException e) {
// 이미 존재해서 발생하는 에러는 무시
log.warn("Consumer Group '{}' already exists for Stream '{}'.", CouponConstants.GROUP_NAME, CouponConstants.STREAM_KEY);
}
} catch (Exception e) {
log.error("Failed to initialize Stream or Consumer Group", e);
}
}
`NOGROUP No such key 'stream-name' or consumer group 'group-name' in XREADGROUP`
Stream에 Consumer Group이 설정되어 있지 않은 상태에서 Consumer Group 읽기(read from group) 를 시도하면 위와 같은 에러가 난다.
그렇기 때문에 프로그램이 실행될 때, 해당 그룹이 없으면 추가하는 로직을 추가했다.
만약 추가할 그룹이 여러 개라면 리스트로 관리하면 될 것 같다.
실행
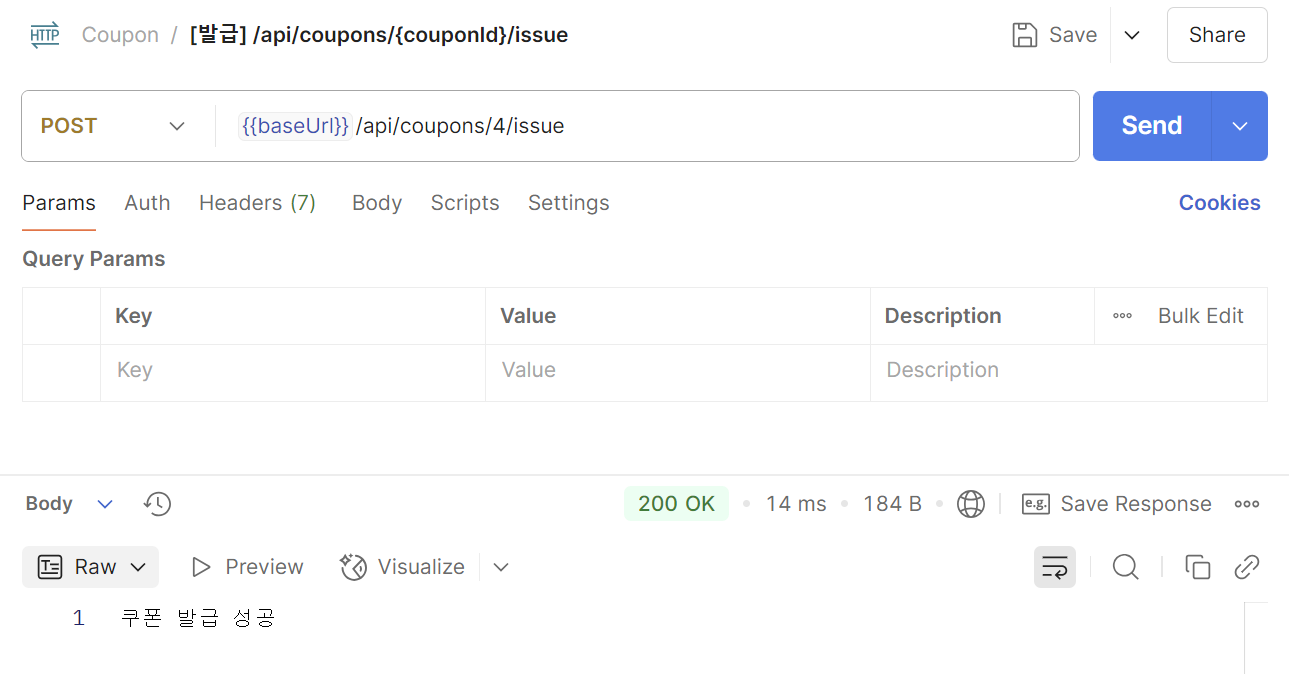
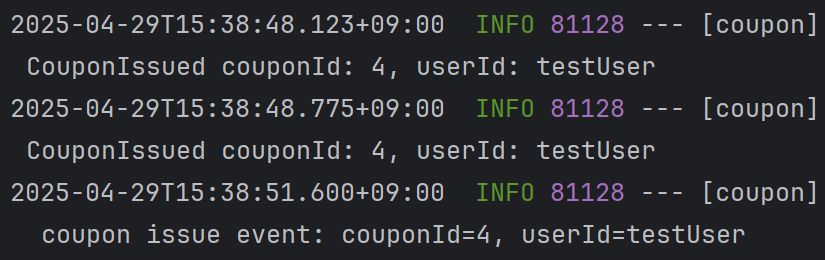
10번 발급 신청을하고 DB 를 확인해보면
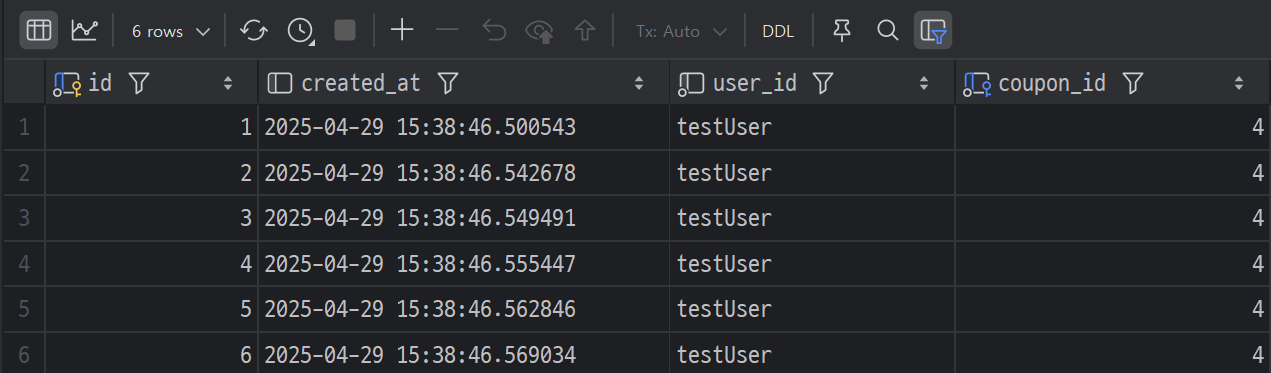
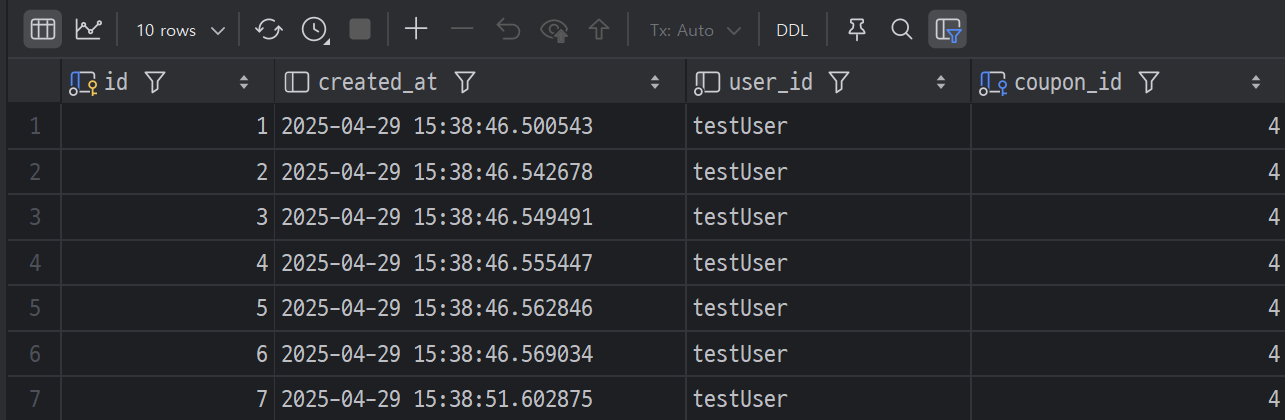
DB에는 6개가 등록된게 확인된다. 나머지는 잠시 후(5초 뒤)에 다시 조회해보면 등록되었다.
지금보니 created_at가 worker에서 save된 시간으로 돼서 create_at도 넘겨줘야할 것 같다...!
'프로젝트 > 쿠폰' 카테고리의 다른 글
| [쿠폰] 테스트를 위한 k6 + InfluxDB + Grafana 구성 (1) | 2025.04.30 |
|---|---|
| [쿠폰] 쿠폰 발급 수정 (saveAll, @Transactional) (0) | 2025.04.29 |
| [쿠폰] 쿠폰 조회 (Redis 예외처리) (0) | 2025.04.28 |
| [쿠폰] 쿠폰 생성 (@Transactional, CustomException) (0) | 2025.04.28 |
| [쿠폰] Redis 선착순 쿠폰 시스템 (1) | 2025.04.28 |